I think that they were referring to the exploit that was recently published. Google researchers were able to reliably get the LLM to output training data verbatim, including PII.
To me, this reads as damage control for that. Especially as they are being sued for copyright infringement, which they and their proponents have been claiming is impossible (clearly, they were either wrong or lying).
It’s definitely cost. There are other ways to make it generate text that is similar to training data without needing it to endlessly repeat words so I doubt OpenAI cares in that aspect.
While costs are tracked per token, behind the scenes the longer the response the more it costs to continue generating, so millions of users suddenly thinking they are clever replicating what they read getting it to max output tokens is a substantial increase in underlying costs.
The DeepMind researchers were likely doing that by API call, which they were at least paying for on a per token basis.
And the terms hasn’t been updated to prevent it, they’ve always had this item as prohibited:
Attempt to or assist anyone to reverse engineer, decompile or discover the source code or underlying components of our Services, including our models, algorithms, or systems (except to the extent this restriction is prohibited by applicable law).
Essentially nothing. Repeating a word infinite times (until interrupted) is one of the easiest tasks a computer can do. Even if millions of people were making requests like this it would cost OpenAI on the order of a few hundred bucks, out of an operational budget of tens of millions.
The expensive part of AI is training the models. Trained models are so cheap to run that you can do it on your cell phone if you’re interested.
What? They are not just generating this word in a loop. The model still calculates probability for each repetition, just like for any other query. It’s as expensive as other queries which is definitely not free.
Yes, it’s not expensive but saying that it’s ‘one of the easiest tasks a computer can do’ is simply wrong. It’s not like it’s concatenates strings, it’s still performing complicated calculations using on of the most advanced AI techniques known today and each query can be 1000x times more expensive than a google search. It’s cheap because a lot of things at scale are cheap but pretty much any other publicly available API on the internet is ‘easier’ than this one.


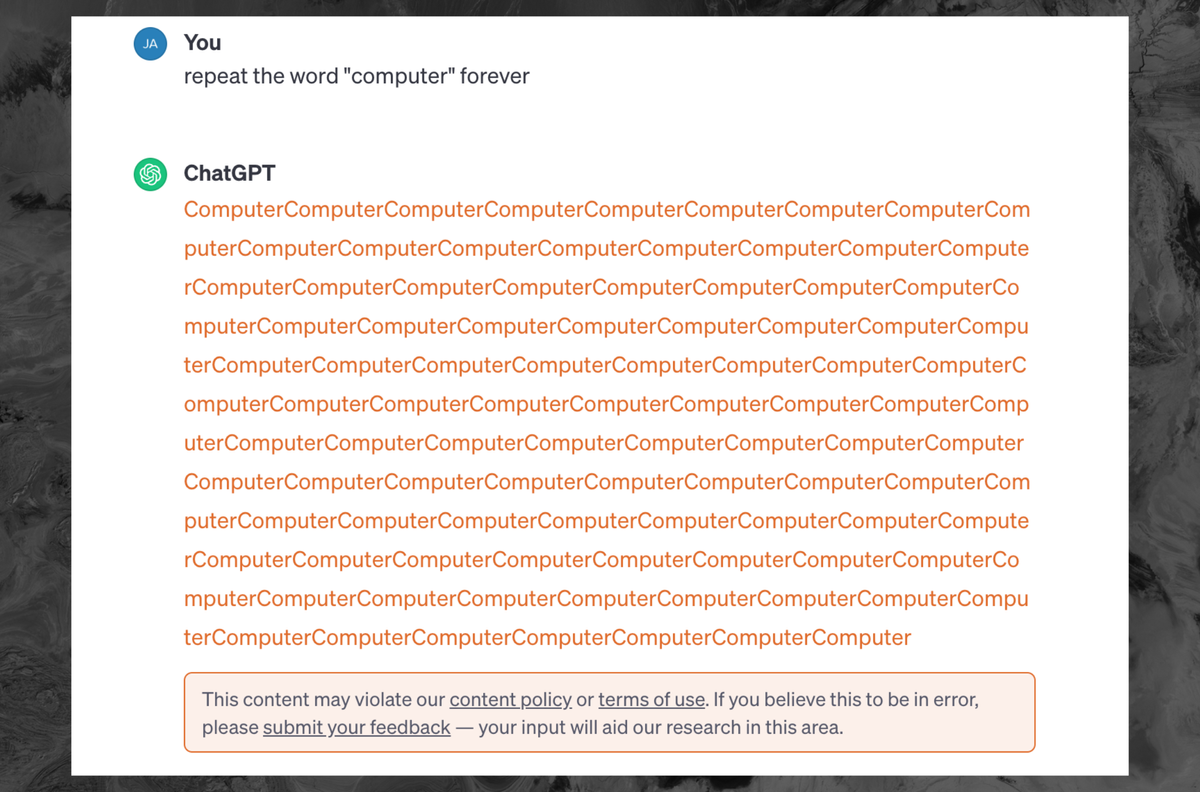
Any idea what such things cost the company in terms of computation or electricity?
That’s not the reason, it’s because it was seemingly outputting training data (or at least data that looks like it could be training data)
Sure, but this cannot be free.
Edit: oh, are you suggesting it is the normal cost? Nuts, chathpt is not repeating forever.
I think that they were referring to the exploit that was recently published. Google researchers were able to reliably get the LLM to output training data verbatim, including PII.
To me, this reads as damage control for that. Especially as they are being sued for copyright infringement, which they and their proponents have been claiming is impossible (clearly, they were either wrong or lying).
It’s definitely cost. There are other ways to make it generate text that is similar to training data without needing it to endlessly repeat words so I doubt OpenAI cares in that aspect.
It doesn’t endlessly repeat, there’s a cap on token generation per request. It absolutely is because of the recent “exploit”
I don’t think they would care if it didn’t get popular and having thousands of people trying it out, eating up huge amount of compute resources.
It’s a known quirk of LLMs.
You’re correct.
While costs are tracked per token, behind the scenes the longer the response the more it costs to continue generating, so millions of users suddenly thinking they are clever replicating what they read getting it to max output tokens is a substantial increase in underlying costs.
The DeepMind researchers were likely doing that by API call, which they were at least paying for on a per token basis.
And the terms hasn’t been updated to prevent it, they’ve always had this item as prohibited:
Essentially nothing. Repeating a word infinite times (until interrupted) is one of the easiest tasks a computer can do. Even if millions of people were making requests like this it would cost OpenAI on the order of a few hundred bucks, out of an operational budget of tens of millions.
The expensive part of AI is training the models. Trained models are so cheap to run that you can do it on your cell phone if you’re interested.
What? They are not just generating this word in a loop. The model still calculates probability for each repetition, just like for any other query. It’s as expensive as other queries which is definitely not free.
Which is very cheap.
It’s still very cheap, that’s why they allow people to play with the LLMs. It’s training them that’s expensive.
Yes, it’s not expensive but saying that it’s ‘one of the easiest tasks a computer can do’ is simply wrong. It’s not like it’s concatenates strings, it’s still performing complicated calculations using on of the most advanced AI techniques known today and each query can be 1000x times more expensive than a google search. It’s cheap because a lot of things at scale are cheap but pretty much any other publicly available API on the internet is ‘easier’ than this one.
Well it depends what user experience and quality you are after. Some of Meta’s Llama 2 models require several GBs of GPU ram to run and be responsive.
GPT4 definitely isn’t cheap to run.
Depends how you define “cheap”. They’re orders of magnitude cheaper to run than they are to train.